- 数组和链表的区别
- 数组
地址连续,查找速度快,操作效率低
存储单元在定义时分配,元素个数固定,内存空间要求高
- 链表
地址不连续,查找速度慢,操作效率高
存储单元在程序执行时动态申请,可按需动态增减
- iOS内存分区的情况,五大区域
- 栈区
Stack
先进后出FILO
由编译器自动分配和释放
栈空间多线程不共享
连续的内存地址,由高向低分配,不会产生碎片
空间较小,运行速度较快,效率高
栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高
- 堆区
Heap
分配方式类似链表,先进先出FIFO
一般需要手动分配和释放
堆内存多线程共享
不连续的内存地址,由低向高分配,容易产生碎片
空间较大,运行速度较慢,效率不如栈
计算机底层并没有对堆的支持,堆是有C/C++函数库提供的,加上碎片问题,导致堆的效率比栈低
- 全局区
全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域.data段,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域.bss段
程序结束后由系统释放
- 常量区
常量字符串就是放在这里的
程序结束后由系统释放
- 代码区
存放函数体的二进制代码
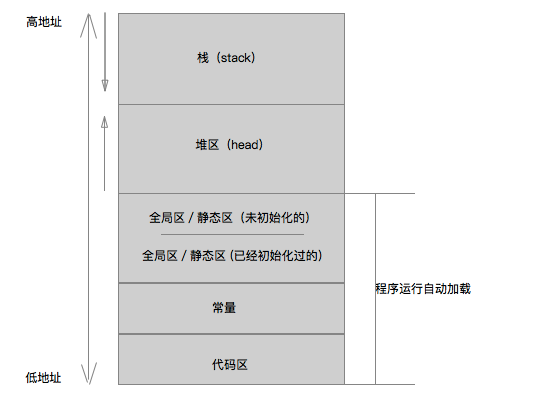
- 当一个app启动后,代码区、常量区、全局区大小就已经固定,因此指向这些区的指针不会产生崩溃性的错误。而堆区和栈区是时时刻刻变化的(堆的创建销毁,栈的弹入弹出),所以当使用一个指针指向这个区里面的内存时,一定要注意内存是否已经被释放,否则会产生程序崩溃(也即是野指针报错)
Hash表
哈希表(Hash table,也叫散列表)是根据键Key直接访问在内存中存储位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。通俗讲就是把Key通过一个固定的算法函数(hash函数)转换成一个整型数字,然后就对该数字用数组的长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。当使用hash表查询时,就是使用hash函数将key转换成对应的数组下标,并定位到该下标的数组空间里获取value,这样就充分利用到数组的定位性能进行数据定位
iOS里有哪些地方用到了Hash表

-------------本文结束感谢您的阅读-------------